
标准化归一化正则化基本概念
标准化(Standardization)通常指将数据进行线性变换,使得数据符合均值为0、标准差为1的正态分布,消除数据量纲的影响。这样不同特征就能有相近的尺度,便于后续分析和建模。简单来说,Z-score标准化就是最常用的方法啦!
归一化(MinMax)则是把数据值缩放到0到1的范围内,使用公式min(x)/(max(x)-min(x))。这种方法主要是消除特征间量级差异,确保所有特征在学习过程中具有同等影响力。举个栗子🌰,在KNN分类中,如果特征值差距很大,归一化就能均衡距离计算,避免某些特征一家独大。
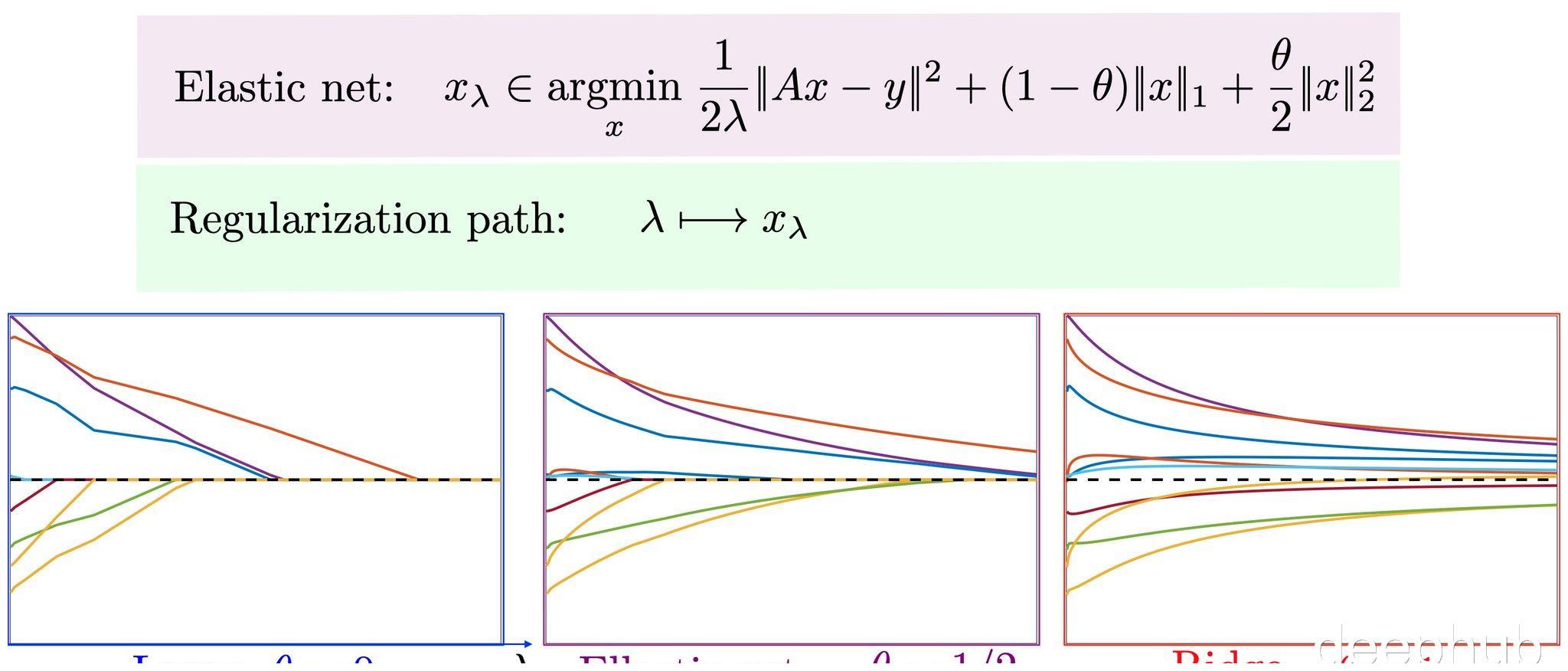
三种方法的具体应用场景
-
标准化适用场景:特别适合大多数机器学习算法,尤其是那些对特征尺度敏感的算法,比如K近邻、支持向量机和线性回归。转换后的数据会遵循标准正态分布,均值为0,方差为1,简直是算法界的万金油!
-
归一化的妙用:适用于需要保持数据原始分布特性的场景,或者算法对数据范围有特定要求的情况。不过要注意哦,这种方法有个小缺陷——当有新数据加入时,可能导致max和min变化,得重新计算,而且最大值最小值容易被异常点影响,鲁棒性稍差。
-
正则化的独特之处:这个方法有点特别,它是依照特征矩阵的行处理数据,目的是让样本向量在点乘运算时拥有统一标准,都变成"单位向量"。在深度学习中,批量归一化(Batch Normalization)超重要,通过对每个小批量数据进行归一化处理,让输入特征尺度一致,大大提升训练稳定性和速度。
在气相色谱分析中,归一化法计算公式为:Xi%=[Ai/(A1+A2+…+An)]·100,校正面积归一化法则是Xi%=[Ai·Fi/(A1·Fi+A2·F2+…+An·Fn)]·100,这些公式在实际应用中超级实用。
相关问题解答
- 标准化和归一化最主要的区别是什么?
哎呀,这个问题问得好!最核心的区别在于处理目的和结果不同哦。标准化是把数据变成均值为0、标准差1的正态分布,主要是消除量纲影响;而归一化则是把数据压缩到0-1范围内,保持原始分布形状。简单说,标准化关注数据分布,归一化关注数据范围,两者适用场景也大不相同呢!
- 为什么机器学习中经常需要数据预处理?
哈哈,这就像做菜前要洗菜切菜一样重要!原始数据往往存在量纲不统一、分布不均匀等问题,直接扔给算法会导致某些特征权重过大,模型效果大打折扣。通过标准化、归一化等预处理,能让数据变得更"规范",提高模型收敛速度和准确率,简直是机器学习不可或缺的准备工作!
- 批量归一化在深度学习中有什么好处?
哇塞,批量归一化可是深度学习中的大杀器!它通过对每个小批量数据进行归一化,让输入特征尺度保持一致,大大提高了训练稳定性。还能加速收敛过程,让模型训练更快更顺利。在实际应用中,选择合适的方法能构建出超高效的深度学习模型,效果杠杠的!
- 如何处理新数据加入时归一化参数变化的问题?
嗯哼,这是个很实际的问题!当新数据加入导致max和min变化时,确实需要重新计算归一化参数。不过可以通过滑动窗口或者指数加权平均等方法来动态调整,减少重复计算。另外,也可以考虑使用更鲁棒的方法,比如中位数和四分位数范围来进行缩放,这样对异常值就不那么敏感啦!
发表评论