
目前反爬虫机制到底能不能有效防止数据被爬取
说实在的嘛,现代的反爬虫机制确实能挡得住很多非专业的爬虫,基本上能保护网站的数据不被随意大规模采集。不过,完全封死也是不大现实,就像“猫抓老鼠”一样,永远都有新的办法绕过防线。
其实,激进的反爬策略还会带来不少副作用,咱们不得不考虑用户体验的问题。比如复杂验证码那玩意儿,虽然拦住了爬虫,但也难免折磨到普通用户,特别是对付搜索引擎爬虫时还可能导致网站排名掉坑里。动态渲染虽然是个好主意,可它增加了服务器负担,也许会让网站跑得没那么爽。换句话说,反爬虫不是越狠越好,安全和用户体验之间得找到个“黄金分割点”。
总的说,反爬虫机制虽然不能做到百分百阻挡,但足够让大多数非专业爬虫望而却步,大大减少被滥用的风险。
服务器能不能拒绝非浏览器发起的HTTP请求 反爬虫策略和SEO还能不能兼顾
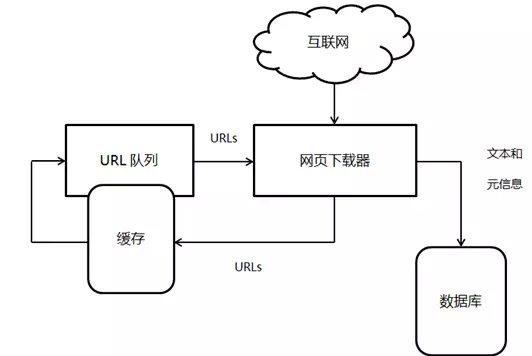
说到服务器拒绝非浏览器请求,这其实是个挺有挑战的事儿。做起来的方法有蛮多,像是Cookie验证、验证码(CAPTCHA)啥的。
比如Cookie验证,就是第一次访问的时候设置个cookie,接下来再访问网站,服务器就会看有没有这cookie,没带cookie的就被拒之门外。不过,这招对付那些自动化工具没啥用,因为它们也能轻轻松松地处理cookie,基本就像老司机一样熟练得很,所以这招适合防护力度不太高的场景。
再说验证码,虽然能有效挡住机器,但代价比较大——那就是牺牲掉了一部分用户体验,只适合用在登录、支付这种关键操作上,否则大家都会哀嚎“太麻烦了,我不上了”。
接下来说说对SEO的影响,不得不承认,过于严格的反爬策略可能会让搜索引擎爬虫蹭不到肉,影响网站排名。好消息是,只要设计得妥妥的,反爬虫和SEO其实是可以兼容的!关键是要懂得“区别对待”,反爬虫的重点是在防恶意高频请求和保护数据安全,而SEO则是为了让网站更容易被人发现。理清这两者目的,采取合理的策略,咱们完全能实现“和谐共处”。
总结几点要注意的:
-
反爬侧重防止恶意行为,比如刷频率给服务器添堵,或盗窃数据。
-
SEO强调爬虫的顺利访问和内容的高效抓取。
-
设计反爬机制时,要留条活路给正规爬虫,不然就拿“灭火器”打“消防员”了。
-
采用分级防护,比如对普通用户友好,对嫌疑IP加码。
-
经常监控和调整策略,让反爬和SEO的天平保持平衡。
相关问题解答
-
现在的反爬虫机制真的能完全挡住爬虫吗?
说真的,完全挡住?哎,不太可能啦!技术永远在进步嘛,又有更聪明的爬虫工具,不停地“变招”,反爬机制只是让爬虫行动变“复杂”、“麻烦”,让绝大多数小白爬虫望而却步。咱们可以把它想成一道门槛,是硬核爬虫要多花点心思才能过,普通的爬虫就知难而退啦。 -
服务器拒绝非浏览器请求是不是挺简单的?
听上去简单,实际操作可没那么容易哦!你得考虑自动化工具的“伪装”技能,比如无头浏览器啥的,能模拟超级逼真的用户行为,还有Cookie、验证码,能起到一定作用,但也要怕影响正常用户体验,真是“得罪不得罪,着急也没用”。 -
反爬虫策略会不会影响搜索引擎优化啊?
嗯,这个问题很实际。反爬虫如果搞得太狠,的确可能让搜索引擎爬虫“被拦”,导致排名下降。但只要策略做得灵活,既防恶意流量又给正规爬虫留路,这俩完全可以和平共处。所以,咱们得智慧地设置“闸门”,让真正的好流量通行无阻。 -
用Python写爬虫要注意什么,才不会踩雷违法?
哎呀,这事儿你懂,遵守规则才能玩得开心。咱们得照着robots.txt的指南走,避免频率太高导致服务器崩溃,也不能随便抓那些有版权限制的数据。还有,商业抓取最好获得授权,不然就容易惹麻烦。要是技术上被反爬限制卡住了,可以用代理、模拟操作啥的,但一定要合理合法,别玩脱了。
发表评论